Research background and motivations
In larger schooling, English teaching is taken into account an important topic, and its teaching high quality and evaluation effectiveness have at all times been a spotlight of consideration1,2,3. Traditional strategies for evaluating English instruction face quite a few challenges, together with a slim evaluation strategy, unscientific evaluation standards, and incomplete data, all of which restrict the potential to reinforce teaching high quality. With the developments in info technology, the combination of massive data and artificial intelligence (AI) has launched new views and methodologies for English teaching evaluation. As a key department of AI, deep studying (DL) presents highly effective data evaluation and sample recognition capabilities, providing strong assist for reforming and innovating English teaching evaluation4,5,6.
Traditional English teaching evaluation depends on academics’ subjective judgment and standardized exams, which regularly results in restricted evaluation dimensions and delayed suggestions. Manual scoring requires substantial time and fails to seize college students’ refined progress. Standardized testing focuses on outcomes whereas neglecting the buildup of process-based data. The introduction of DL and data mining applied sciences can tackle these limitations via automated scoring, multidimensional data evaluation, and real-time suggestions mechanisms. However, present analysis nonetheless lacks in algorithm integration and adaptability of evaluation fashions, which is the first focus of this research. DL allows personalised studying by recommending sources and actions suited to college students’ habits, skills, and wants. Such personalization is crucial for fostering autonomous studying and enhancing English language competence. Data mining refers back to the strategy of extracting helpful info and data from massive datasets, together with clustering evaluation, affiliation rule mining, classification, and prediction7,8,9. In the context of faculty English evaluation, data mining can be utilized to research pupil conduct and consider teaching high quality. This research goals to assemble an environment friendly and equitable evaluation framework by integrating DL with data mining applied sciences to satisfy the sensible wants of large-scale instructional settings.
Research hole
Most present work focuses on the remoted utility of data mining strategies, overlooking the collaborative potential of mixing architectures like Transformer with Bayesian frameworks to attain personalised studying. Previous research normally combination pupil data with out analyzing gender variations in studying preferences and talent priorities. As a consequence, the shortage of clear mannequin architectures prevents educators from auditing the contribution of various capabilities. This research addresses the hole via interpretable resolution guidelines and goals to fill these deficiencies by using a transformer–Bayesian built-in framework and combining behavioral sequences with multi-source evaluation data.
Research targets
This work goals to advance the reform and innovation of English teaching evaluation and obtain personalised English instruction via the applying of DL and AI-driven data mining strategies. By analyzing and summarizing the present state of related analysis, this work explores the function of DL in English teaching fashions and proposes a Bayesian strategy to personalised instruction. Simultaneously, using AI data mining strategies, a brand new English teaching evaluation methodology is launched to reinforce teaching high quality and evaluation effectiveness.
With the continual improvement of data mining and DL applied sciences, their utility prospects in faculty English teaching evaluation have gotten more and more broad. This work goals to discover the sensible utility of those applied sciences in teaching, and present new concepts and strategies for school English schooling. The particular analysis questions embody: How can college students’ studying conduct data be analyzed to foretell their examination scores? Which elements have probably the most important impression on the event of scholars’ English proficiency? Section 1 describes the analysis background, targets, and necessity. Section 2 summarizes the present analysis standing of DL and AI data mining in English teaching. Section 3 primarily focuses on exploring English teaching fashions primarily based on DL, proposing the Bayesian methodology for personalised English instruction, and introducing an English teaching evaluation methodology primarily based on AI data mining. Section 4 focuses on experimental evaluation, together with dataset processing and consequence prediction. Section 5 concludes contributions and limitations, and suggests future analysis instructions. This work efficiently applies the Transformer structure, initially from the sphere of pure language processing (NLP), to the schooling sector. This interdisciplinary integration not solely expands the applying scope of the Transformer structure but in addition introduces novel strategies for data processing and evaluation in schooling. By leveraging the highly effective characteristic extraction and sequence modeling capabilities of the Transformer, this strategy allows a deeper understanding of scholars’ studying behaviors, facilitating extra correct personalised teaching assessments.
Literature overview
In the sphere of language schooling, notably English teaching, the speedy improvement of DL and AI applied sciences has introduced the standard of instruction and evaluation to the forefront of consideration in each tutorial and sensible domains. This part focuses on the applying and impression of DL/AI in language schooling. Vaswani et al. (2017)10 proposed a novel and easy community structure that was completely primarily based on the eye mechanism, fully eliminating the necessity for recursion and convolution. Numerous research have highlighted the importance of English teaching in larger schooling. Eke et al. (2021)11 identified that English teaching not solely enhanced college students’ cross-cultural communication expertise but in addition performed an important function in fostering a world perspective and competitiveness. Similarly, Lu & Vivekananda (2023)12 emphasised the significance of English teaching high quality in enhancing college students’ total competencies and employability. These research present a strong theoretical basis for exploring the applying of DL in language schooling. However, conventional teaching strategies have limitations in relation to assessing college students’ English proficiency. To tackle these limitations, Peng et al. (2022)13 started exploring the applying of DL/AI in language schooling. Their analysis revealed that by leveraging huge data and machine studying algorithms, pupil proficiency in English could possibly be assessed extra precisely, enabling the availability of extra personalised teaching methods. This discovery presents new insights and strategies for innovation in language schooling.
In discussing how DL technology enhances English teaching and helps personalised studying, the main focus must be its purposes in NLP, studying useful resource suggestion, and sentiment evaluation. DL technology can comprehend and course of language info extra deeply by mimicking the human mind’s info processing. This functionality is essential for enhancing the standard and effectivity of English teaching. Next, the purposes and effectiveness of DL technology in these areas are particularly analyzed. Zhu et al. (2021)14 utilized DL’s NLP strategies to design a system that completely understands and processes college students’ language inputs. This system allows extra correct semantic evaluation and grammar correction, thereby enhancing college students’ language utility expertise. Additionally, the system can assess college students’ writing in actual time and present focused strategies for grammar and vocabulary enhancements, essentially enhancing college students’ writing proficiency. Concurrently, Agüero-Torales et al. (2021)15 proposed using DL suggestion algorithms to research college students’ studying journeys, preferences, and efficiency. This methodology precisely recommends probably the most appropriate studying sources and actions, additional reaching the purpose of personalised studying. Zhong et al. (2020)16 utilized DL to sentiment evaluation, and designed a system able to decoding college students’ emotional suggestions on studying supplies. This sentiment evaluation system allows academics to adapt their methods to satisfy college students’ particular person wants and rapidly identifies studying challenges or areas of curiosity, facilitating focused intervention and assist. The utility of DL technology in English teaching is multifaceted. This not solely enhances college students’ language proficiency but in addition offers tailor-made suggestions for studying sources primarily based on their progress and preferences. Additionally, the sentiment evaluation offers academics with deeper insights into college students’ wants, permitting for extra custom-made instruction. These developments not solely elevate the standard of personalised teaching but in addition equip educators with various methods and strategies, enhancing teaching effectivity and precision. As DL technology continues to evolve, it’s affordable to count on an much more important impression on English schooling, enriching college students’ studying experiences and offering higher-quality instructional outcomes.
In trendy society, the speedy development of massive data and AI technology is reworking the academic panorama, particularly within the evaluation of English teaching in larger schooling. These improvements have redefined conventional teaching fashions, introducing new views and methodologies for evaluation. To improve the standard of schooling and the effectiveness of assessments, researchers are more and more integrating these applied sciences into English teaching evaluation, striving for improved instructional outcomes. Dang et al. (2020)17 proposed a DL-based automated scoring mannequin for English composition, successfully enhancing scoring effectivity and accuracy. Kumar (2020)18 utilized affiliation rule mining strategies to research college students’ English scores, discovering potential teaching points and developments. In phrases of analysis strategies, researchers have utilized varied approaches and technological instruments to validate the effectiveness of their analysis hypotheses and fashions. For occasion, Mostafa and Benabbou (2020)19 carried out experiments evaluating conventional grading strategies with DL-based grading strategies, gaining helpful insights into college students’ and academics’ perceptions and experiences with AI-based teaching evaluation. The findings indicated a higher acceptance of superior teaching evaluation strategies amongst each educators and learners.
With the development of laptop technology and AI, clever evaluation has made important progress in evaluating college students’ skills and data ranges. Kartika et al. (2023)20 argued that clever evaluation might diagnose and analyze college students’ particular topic data and competencies primarily based on intensive longitudinal studying data, enabling modeling and dynamic evaluation of the training course of. Tang et al. (2022)21 talked about strategies similar to simulation-based and game-based assessments, which supplied college students with full, genuine, and open downside contexts, permitting them to discover and specific themselves freely inside activity situations. Maghsudi et al. (2021)22 employed DL technology to develop pupil fashions and studying useful resource suggestion methods, providing personalised studying paths and sources tailor-made to college students’ studying situations and pursuits.
These research display the large potential and precise effectiveness of massive data and AI applied sciences in English teaching evaluation. These applied sciences not solely improve the effectivity and accuracy of scoring but in addition facilitate the identification of teaching points and developments, thereby offering proof for teaching enhancements. Furthermore, comparative experiments with conventional evaluation strategies allow researchers and educators to intuitively grasp the advantages of AI-driven evaluation approaches, fostering innovation and improvement in instructional technology.
Research mannequin
The framework proposed combines the sequence modeling capabilities of the Transformer structure with Bayesian inference for personalised studying. The Transformer structure makes use of a self-attention mechanism to seize temporal dependencies in studying behaviors, modeling the “learning input-performance output” relationship via an encoder-decoder construction. A Monte Carlo dropout approximation is launched to mannequin uncertainty, and Bayesian posterior distributions are used to combine multimodal evaluation data, enhancing the robustness of predictions.
Personalized english teaching in faculty primarily based on DL
The central idea of personalised studying is to handle the person variations that come up in the course of the studying course of. Each learner possesses distinct traits, similar to distinctive studying preferences and particular areas of weak spot. Consequently, personalised studying adopts a custom-made strategy, offering tailor-made studying recommendation and strategies primarily based on every person’s studying context. This individualized methodology goals not solely to assist college students bridge data gaps but in addition to domesticate curiosity and confidence in unfamiliar topics.
In implementing personalised studying, varied instruments and strategies may be employed, similar to interactive skill exams, to comprehensively assess learners’ studying processes and acquire a clearer understanding of their strengths and weaknesses23,24. Internet-based schooling platforms present a handy area for personalised studying, enabling college students to pick acceptable sources primarily based on their wants and studying tempo. Meanwhile, efficient studying methods are important on this course of. Comprehensive assessments, pre-class quizzes, and post-class quizzes can improve college students’ deep understanding and mastery of information, making personalised studying an environment friendly and efficient instructional mannequin.
In making use of Bayesian statistics primarily based on DL in schooling, the elemental idea is to deal with a pupil’s studying effectivity as a chance distribution that evolves over time25,26,27. By meticulously observing and recording every occasion of a pupil’s studying exercise, the system can repeatedly replace the evaluation of the coed’s studying effectivity, making certain it aligns extra intently with their precise circumstances. This personalised strategy to evaluating studying effectivity successfully addresses particular person variations amongst college students, enabling extra focused suggestions for studying methods and sources. According to Bayesian theorem, the posterior distribution of a pupil’s studying effectivity may be represented as:
$$Pleft( D proper. proper)=frac{{Pleft( theta proper. proper) cdot Pleft( theta proper)}}{{Pleft( D proper)}}$$
(1)
(theta) represents the coed’s studying effectivity, and D is all noticed studying data. (Pleft( D proper. proper)) is the posterior chance of (theta) given data D; (Pleft( theta proper. proper)) is the chance (probability) of observing data D given studying effectivity (theta); (Pleft( theta proper)) is the prior distribution of pupil studying effectivity, that’s, the effectivity earlier than observing any data; (Pleft( D proper)) is the marginal chance of data D.
In mathematical statistics, the probability operate is a operate of the parameters of a statistical mannequin that expresses the probability of these parameters. The probability operate is essential for statistical inference, together with purposes similar to most probability estimation and Fisher info. While the phrases “likelihood,” “plausibility,” and “probability” are intently associated and all consult with the prospect of an occasion occurring, they’ve distinct meanings in a statistical context.
Probability is employed to foretell the outcomes of future observations given sure parameters are recognized, whereas chances are utilized to estimate the parameters of curiosity given sure noticed outcomes. Specifically, given the output x, the probability operate (Lleft( x proper. proper)) about parameter (theta) (numerically) equals the chance of variable (X=x) given parameter (theta):
$$Lleft( x proper. proper)=Pleft( theta proper. proper)$$
(2)
To consider the probability operate for parameter (theta), it’s numerically equal to the conditional chance of observing consequence X given parameter (theta), which is also referred to as the posterior chance of X. Generally, the next worth of the probability operate signifies that parameter (theta) is extra believable given the result (X=x). Therefore, formally, the probability operate is a kind of conditional chance operate, however with a shift in focus: this work is within the probability worth for A taking the parameter (theta).
$$theta leftlangle { – – } rightrangle Pleft( {Bleft| {A=theta } proper.} proper)$$
(3)
Through interactive steering, college students can personally expertise their progress in every English studying session and obtain the system’s optimistic suggestions on completely different studying states. This personalised suggestions mechanism enhances college students’ understanding of their efficiency within the course, fostering enthusiasm and confidence of their studying journey.
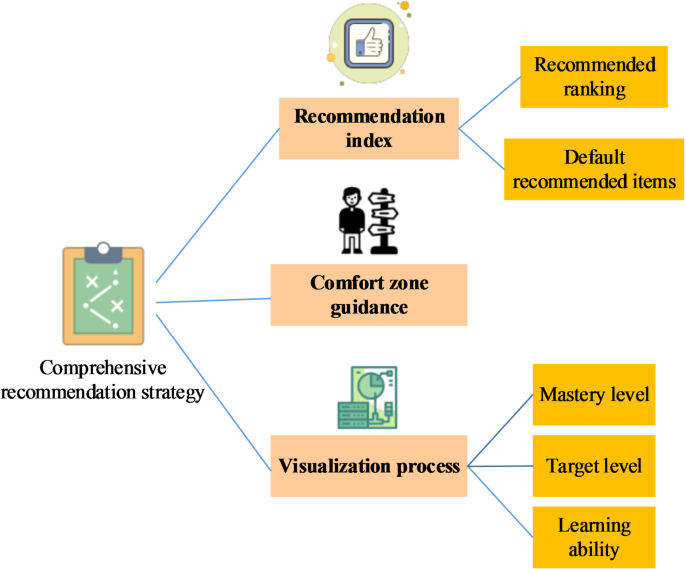
This work primarily investigates the design of efficient steering methods to assist various college students full their coursework extra effectively and tackle their personalised studying wants. Figure 1 illustrates the excellent suggestion technique for English teaching. The system leverages built-in suggestions and indices to supply content material strategies that align extra intently with customers’ studying necessities, thereby accelerating the training course of28,29,30. Additionally, it emphasizes consolation zone steering as a suggestion strategy, enabling customers to steadily broaden their studying consolation zones, which facilitates a smoother progress trajectory. Ultimately, by fostering situational studying pursuits, the system can acquire a holistic understanding of customers’ studying wants and present a extra participating and personalised instructional expertise. The built-in utility of interactive steering and steering methods seeks to stimulate college students’ optimistic attitudes in direction of studying, improve their enthusiasm for studying, and finally obtain simpler studying outcomes31,32. In the Bayesian framework, figuring out and updating the prior distribution are key steps. This work employs a statistical evaluation methodology primarily based on historic data to find out the prior distribution and updates it in real-time to accommodate college students’ studying progress. This dynamic replace mechanism ensures that the mannequin precisely displays the scholars’ true studying state of affairs. Whenever new studying data is generated, the posterior distribution is recalculated primarily based on Bayes’ theorem and used because the prior distribution for the following prediction.

Comprehensive suggestion technique in English teaching.
Process of AI data mining
Data mining is the method of uncovering hidden info inside massive datasets using algorithms. This course of, typically related to laptop science, employs varied strategies similar to statistics, on-line analytical processing, info retrieval, machine studying, knowledgeable methods, and sample recognition33,34,35. The data mining course of contains steps like data preparation, integration, choice, and preprocessing. Its major purpose is to find data that’s related, comprehensible, relevant, and supportive of particular utility discovery challenges.
In data mining, the choice tree algorithm is a supervised studying algorithm utilized for classification and regression issues36,37,38. It constructs a call tree by recursively dividing the dataset into smaller subsets. In this building, every node represents a take a look at situation for a characteristic attribute, and every department corresponds to the result of that characteristic attribute in a particular worth vary. Each leaf node shops a class or a particular numerical worth. This work adopts a characteristic choice methodology primarily based on info acquire. Specifically, the knowledge acquire of every characteristic relative to the goal variable is calculated, and the highest N options with the best info acquire are chosen as mannequin inputs. During the development of the choice tree, the Gini index is used because the splitting criterion. A smaller Gini index signifies larger node purity. The resolution tree is constructed by recursively choosing the optimum splitting characteristic and splitting level. Table 1 exhibits some great benefits of the choice tree methodology in comparison with neural networks and assist vector machines.
Microsoft’s resolution tree algorithm constructs environment friendly data mining fashions by rigorously designing a collection of splits within the tree construction. Figure 2 is the construction of the choice tree mannequin. Whenever the algorithm identifies a major correlation between a column within the enter data and the predictable column, it introduces a brand new node into the mannequin. The building strategy of the Microsoft resolution tree begins by treating all the dataset as a single node. The purpose is to partition the pattern set primarily based on a specific attribute to purify the category distribution within the subnodes as a lot as doable. This course of depends on choosing the optimum cut up level to both maximize info acquire or decrease Gini impurity, thus reaching efficient classification of the samples. T The partitioning stops when all samples belong to the identical class or when the preset most depth is reached; in any other case, the perfect cut up level is chosen for additional partitioning. Ultimately, the category of every leaf node is decided primarily based on the precept of “the majority rules.” This course of not solely helps to grasp college students’ studying conduct patterns but in addition offers robust assist for personalised teaching. In phrases of characteristic choice, the Microsoft resolution tree primarily considers the frequency of characteristic occurrences and their proximity to the foundation node. Features that incessantly seem and are nearer to the foundation are typically thought-about to have a higher impression on classification outcomes. Here, completely different query kind scores and examination efficiency are recognized as key elements influencing college students’ success in exams, and the place of those options within the resolution tree displays their significance. Moreover, info acquire, as one of many characteristic choice standards, measures the extent to which a specific attribute enhances classification purity, whereas Gini impurity is adopted to quantify the chance of parts inside a set being misclassified. These two strategies work collectively to make sure that the mannequin successfully captures the important thing info within the data.

The construction of the choice tree mannequin.
The Microsoft resolution tree algorithm makes use of “feature selection” to find out probably the most helpful attributes. These strategies assist forestall irrelevant attributes from consuming processor time, thus enhancing efficiency, and enhancing the standard of research. Figure 3 illustrates the choice tree constructing course of. This algorithm is primarily utilized in data mining and machine studying, aiding customers in extracting helpful info and data from massive datasets. By constructing resolution tree fashions, customers can uncover associations and patterns inside the data, making use of these insights to sensible challenges similar to fraud detection and credit score scoring39,40.
The dataset used on this research incorporates textual options, numerical options, and categorical labels, displaying traits of high-dimensional blended data. The resolution tree algorithm is chosen as the popular methodology as a result of it requires no complicated preprocessing and can instantly deal with each categorical and steady variables. The dataset contains 1,500 samples with a average variety of options, permitting the choice tree to strike a great steadiness between computational effectivity and mannequin interpretability. In distinction, neural networks, though able to capturing complicated patterns, are usually not the optimum selection on this context attributable to their black-box nature and excessive computational value.

The resolution tree constructing course of in Microsoft resolution tree algorithm.
In the preliminary phases of data mining, data preprocessing is an important step that encompasses data cleansing, transformation, characteristic extraction, and extra. For textual data similar to pupil assignments and classroom discussions in English teaching evaluations, the Transformer structure can deal with such unstructured data. Through preprocessing strategies like tokenization, stop-word elimination, and phrase embedding, textual data are transformed into numerical data that fashions can course of. The Transformer structure, a major development in recent times in NLP, excels in capturing long-range dependencies inside sequences and dealing with complicated textual data, providing contemporary insights into English teaching evaluations. This work builds on the foundations of data mining and makes use of the Transformer structure in English teaching evaluations. It leverages the mannequin’s highly effective characteristic extraction and sequence modeling capabilities to attain a complete understanding and correct evaluation of scholars’ English studying experiences. The Transformer structure employs a multi-head consideration mechanism, particularly with 8 consideration heads, every having a dimension of 64. This configuration helps the mannequin seize richer info whereas sustaining computational effectivity. The mannequin is educated using the Adam optimizer, with a studying charge set at 0.001. To forestall overfitting, dropout technology is adopted, with a charge of 0.2. During coaching, the loss operate and accuracy on the validation set are monitored, permitting for changes to the training charge and early stopping technique as wanted.
A multi-layer encoder-decoder mannequin is constructed primarily based on the Transformer structure. The encoder transforms enter textual data right into a collection of characteristic vectors, whereas the decoder generates evaluations of pupil studying primarily based on these characteristic vectors. During mannequin building, parameters and constructions are adjusted to satisfy particular necessities, optimizing efficiency. The self-attention mechanism, which is central to the Transformer mannequin, captures dependencies between any two positions inside the sequence. Attention weight calculation reads:
$$Attention(Q,Ok,V)=softmax(frac{{Q{Ok^T}}}{{sqrt {{d_k}} }})V$$
(4)
In this context, Q represents the question matrix, Ok is the important thing matrix, and V is the worth matrix. ({d_k}) refers back to the dimensionality of the important thing vectors, used to scale the dot product to mitigate the problems of gradient vanishing or exploding.
Based on the evaluation outcomes from the Transformer mannequin, personalised studying suggestions and teaching methods may be tailor-made for every pupil. For occasion, college students who battle with grammar could possibly be supplied with extra workout routines and explanations, whereas these with weak oral expression expertise would possibly obtain sources for oral apply and pronunciation correction. By using personalised evaluation methods, educators can extra successfully tackle college students’ studying wants and enhance total teaching effectiveness. In the precise implementation of the Transformer structure, specific consideration is given to the configuration of the eye heads and the optimization of the coaching course of. By rigorously configuring the eye heads and adopting efficient coaching methods, the mannequin is ready to effectively course of complicated textual content data and extract helpful info for school English teaching evaluation.
DL path in english teaching
Combining Eric Jensen and LeAnn Nickelsen’s DL path (Fig. 4), academics ought to first make clear teaching objectives and expectations. They ought to make sure that college students not solely grasp basic data and expertise in English but in addition develop cross-cultural consciousness and self-directed studying skills.

The roadmap for college kids’ DL in English teaching.
This work develops a DL mannequin tailor-made to the traits of faculty English teaching, combining the strengths of Bayesian strategies and the Transformer structure to attain personalised teaching assessments. The mannequin’s enter contains multidimensional data similar to college students’ studying information, project completion charges, classroom interplay data, and on-line studying behaviors. After preprocessing, these data are reworked into characteristic vectors for mannequin enter. In the preliminary part, a Bayesian community layer is employed to deal with uncertainty. This community infers college students’ future studying potential and doable obstacles primarily based on present studying data and historic efficiency. Its objective is to offer a probability-based preliminary evaluation for the following Transformer structure, aiding the mannequin in understanding particular person variations amongst college students. Following this, the Transformer structure processes college students’ time collection data. Comprising an encoder and a decoder, the encoder extracts options from the enter data, whereas the decoder generates outputs primarily based on these options. In this mannequin, the encoder handles college students’ studying information and associated data, using a self-attention mechanism to seize complicated relationships inside the data. The decoder then produces personalised teaching evaluation outcomes and predictions primarily based on the encoder’s output. In the pre-assessment stage, academics should consider college students’ English proficiency and skills to determine their beginning factors and establish areas needing consideration. This evaluation allows academics to pinpoint college students’ confusions and challenges in English studying, thereby facilitating the event of focused teaching methods.
In order to create an surroundings conducive to DL, academics ought to provide a various array of studying supplies and sources, together with textbooks, on-line sources, and multimedia supplies41,42,43. These sources not solely broaden college students’ data but in addition improve their curiosity and motivation to be taught. Additionally, academics have to create genuine contexts via situational simulations, role-playing, and related strategies, enabling college students to attach English with real-life conditions and develop cross-cultural communication expertise.
In activating college students’ prior data, academics can make use of strategies similar to questioning, dialogue, or offering related circumstances to assist college students recall and affiliate beforehand discovered content material. This course of facilitates the combination of recent data with present understanding, resulting in deeper comprehension and that means44,45,46.
Acquiring new data is an important step in DL. Teachers should clarify, display, and information college students in mastering new vocabulary, grammar, and expressions. In the deep processing stage, they need to information college students in summarizing and organizing what they’ve discovered to construct a cohesive data system. Additionally, academics ought to design tasks or duties that permit college students to use English in real-life conditions, fostering their revolutionary considering and problem-solving expertise47. These actions not solely assist within the internalization of information but in addition improve college students’ language proficiency and cross-cultural communication expertise. In this research, college students are divided into an interactive group (n = 145) and a non-interactive group (n = 145). The former makes use of an AI-driven real-time suggestions system, whereas the latter relys on conventional instruction. Classroom actions within the interactive group embody NLP-based instantaneous essay correction and personalised studying path suggestions. In distinction, the non-interactive group solely receives uniform explanations from the instructor.