
Public values on AI
This research has chosen “Artificial Intelligence (AI)” because the goal know-how discipline for evaluation. AI is a promising know-how space related to the Fourth Industrial Revolution, with important hyperlinks to public worth and underlying points. In addition, there’s a wealthy availability of R&D efficiency knowledge, together with patents and tutorial papers, and quite a few know-how influence reviews revealed globally, making it appropriate for evaluation. As introduced in numerous reviews, Table 2 summarizes the public worth of AI know-how. The six public worth classes launched in Sect. 2.3 (industrial developments, protected society, sustainable surroundings, job creation, human well being, and comfort of life) have been outlined based mostly on authoritative nationwide and worldwide R&D planning and analysis paperwork. These classes have been chosen to seize dimensions which are well known and relevant throughout totally different generations of know-how growth. The framework additionally stays open to evolution, permitting classes to be added, refined, or eliminated as new public worth dimensions emerge in future contexts. For occasion, “safe society” consists of points such because the alternative of hazardous jobs and privateness safety, whereas “sustainable environment” highlights challenges like carbon neutrality and environmental safety. Job creation, in flip, is predicted to happen through new employment types and classes.
Moreover, AI know-how contributes to human well being by way of welfare companies and healthcare functions and enhances comfort and effectivity in day by day life, thus producing public worth in numerous methods. Considering these numerous facets of public worth, AI has established itself as a major space for R&D efficiency evaluation. This offers a basis for policymakers and researchers to know and handle the social impacts of AI know-how systematically.
Research framework
Countries implement numerous R&D applications through which universities and analysis institutes conduct analysis initiatives with nationwide assist, producing analysis outputs resembling patents and publications. These outputs collectively contribute to long-term societal impacts and embody numerous types of public worth. This research evaluates the societal results of R&D applications through the lens of “public value” derived from nationwide R&D insurance policies. To obtain this, a framework was developed to evaluate public worth by analyzing direct R&D outputs (e.g., patents and publications) and exterior sources discussing social impacts (e.g., information articles, columns, and reviews) through textual content evaluation, as demonstrated in Fig. 1. This framework prioritizes content material evaluation, specializing in the drivers and anticipated results associated to public worth fairly than relying solely on quantitative metrics of R&D outcomes.
In addition, the framework considers the hierarchical construction of R&D—spanning from particular person initiatives to applications and insurance policies. It aggregates outcomes analyzed on the R&D output degree to supply an analysis on the R&D program degree. This method permits comparative evaluation by know-how space, funding sort, and 12 months, making it worthwhile for assessing science and know-how coverage efficiency and guiding future coverage growth.
.

Research idea linking R&D insurance policies, applications, and outputs to societal impacts represented by six public worth classes.
This research develops a public worth analysis framework for public R&D efficiency based mostly on textual content evaluation, structured in the next three levels in Fig. 2: (1) Data assortment: In this primary stage, textual content paperwork and bibliographic info associated to R&D outputs derived from public insurance policies and exterior sources are collected. Information linking R&D program, R&D mission, and R&D output is gathered with the National Technology Information Service (NTIS) to attain this. Raw knowledge on R&D outputs (resembling patents and publications) from NTIS is collected, together with exterior sources associated to the goal know-how space, together with information articles, columns, and reviews. (2) PV extraction: In the second stage, the consultant mannequin of pre-trained LLMs, particularly GPT-3.5, is utilized to extract public values from analysis outcomes based mostly on a public worth classification job. This entails proposing a course of for analyzing public values through immediate engineering based mostly on API. GPT determines the public worth varieties which are embodied in the analysis outputs and extracts associated phrases. (3) R&D coverage analysis: In the third stage, a course of is printed to derive the analysis outcomes on the R&D program degree from the public worth extracted on the R&D output degree. Public values which are troublesome to determine straight on the R&D output degree are expanded by analyzing the connections between R&D outputs and exterior sources to current the outcomes.

Module 1: knowledge assortment
In the primary module of this research, a complete dataset is constructed by exploring numerous databases to gather nationwide R&D outcomes in the AI discipline. The NTIS, which offers open knowledge from Korean public establishments, is utilized to collect a listing of nationwide R&D achievements in AI know-how. In addition, patent knowledge is collected from the United States Patent and Trademark Office (USPTO), together with titles, abstracts, and full texts of patent specs (description, background).
Unlike earlier research that primarily targeted on abstracts, this research makes use of your complete textual content of patent specs. Specific chapters inside the full patent texts, resembling “Background,” “Effect of the Invention,” and “Advantageous Effect,” include content material associated to public worth expectations from the know-how growth. Academic papers might be one other DB for R&D outputs, together with titles, abstracts, and full texts.
To seize broader views past direct R&D outputs, this research additionally integrated information articles, with a give attention to opinion and column items. These sources, in contrast to patents, present interpretive discussions that synthesize skilled viewpoints, trade developments, coverage debates, and societal views. By together with information articles, the dataset enhances the technical focus of direct R&D output resembling patents. Additional knowledge sources mirror narrative parts typically discovered in different R&D outputs resembling mission reviews, datasets, or coverage briefs. This dual-source technique permits a extra balanced evaluation of public worth, together with underrepresented varieties resembling job creation and social influence.
This research focuses on R&D outputs in the type of patents, which permits detailed technical evaluation however could introduce bias by excluding different output varieties resembling tutorial papers, mission reviews, or datasets that might reveal further dimensions of public worth. While this methodological focus enhances methodological consistency, it limits the scope of the findings to patented applied sciences. The evaluation additionally depends on natural language processing strategies, particularly utilizing an LLM classifier, making the accuracy of outcomes depending on mannequin efficiency. However, current advances in LLMs have demonstrated excessive sensible efficiency in textual content classification and semantic understanding, making them more and more dependable for large-scale evaluation in analysis contexts38,39. In addition, the dataset consists of qualitative textual content describing inherently subjective public worth (PV) parts. To handle the interpretive challenges related to such qualitative knowledge, this research proposes a scientific framework for figuring out and categorizing PV from patent paperwork, enabling extra structured and reproducible interpretations.
Module 2: PV extraction
This research makes use of the pre-trained mannequin GPT-3.5-turbo supplied by OpenAI. Module 2 proposes a way for using the GPT mannequin to research public values. GPT-3.5-turbo is a extremely environment friendly and versatile LLM that builds on the strengths of GPT-3 whereas providing improved efficiency and cost-effectiveness, making it a pretty possibility for a variety of functions in NLP. The GPT mannequin permits for immediate engineering, which is the method of designing and adjusting enter prompts to make the most of language fashions like AI successfully. This permits the AI mannequin to be utilized extra precisely and successfully. Here, texts associated to the impacts of novel applied sciences are enter into the mannequin. The mannequin then classifies the kinds of public worth and offers the related phrases that assist its classification. The research additionally references tips from earlier analysis to make sure systematic immediate engineering of the GPT mannequin. The mannequin handles a number of duties for a single textual content enter, together with public worth sort classification, offering relevance scores for every labeled sort, and extracting related phrases for every classification. The research employs a “chain-of-thought” (CoT) method to reinforce the effectiveness of those advanced duties.
CoT prompting guides the mannequin through intermediate steps or ideas that result in the ultimate output. This method is especially helpful for advanced duties that require multi-step reasoning, resembling fixing mathematical issues, logical reasoning, or answering questions that contain a number of layers of knowledge40. The key concept behind CoT prompts is to interrupt down the problem-solving course of into smaller, extra manageable steps. This method permits the mannequin to know higher and incrementally clear up the issue, providing enhancements in accuracy, transparency, and error detection41.
The prompts proposed right here for extracting public values are structured as follows. Initially, the consumer offers an preliminary immediate targeted on the public worth classification job. In the intermediate steps, the mannequin is requested to supply a relevance rating for the public worth classification and to determine associated phrases. Finally, the method concludes with a request for the ultimate output derived from the CoTs.
One of the key challenges of adopting LLMs like GPT is the issue in making certain transparency as a result of advanced and huge nature of the mannequin’s structure. This makes it difficult to confirm whether or not the mannequin’s output is correct. However, the step-by-step immediate methodology proposed right here addresses this situation by offering relevance scores and associated phrases alongside the public worth classification. This permits the end-user to make the most of these further items of knowledge because the rationale for his or her last judgment. Rather than merely accepting the public worth classification supplied by the GPT mannequin, we recommend the person is inspired to make a complete determination based mostly on a number of judgment factors outlined right here. These embody whether or not a category with a excessive relevance rating was recognized, whether or not the related phrases have been extracted for the category with the excessive relevance rating, and whether or not the phrases semantically associated to the public worth class have been appropriately extracted. By validating the consistency and appropriateness of the detailed outputs supplied by the mannequin, solely essentially the most strong outcomes are reviewed and finally outlined as the ultimate PV.
This research presents the proposed framework as a proof-of-concept to exhibit the feasibility of extracting and analyzing public worth from large-scale unstructured R&D outputs utilizing GPT-based NLP. While the present work focuses on illustrating the workflow with a considerable dataset, the framework might be prolonged to quantitatively consider accuracy, bias, and reproducibility. Accuracy may very well be assessed by making a gold-standard subset for skilled labeling and calculating precision, recall, and F1-score42. Bias may very well be examined through statistical parity or disparate influence metrics43, and reproducibility measured utilizing settlement statistics resembling Cohen’s kappa44,45. Benchmarking may contain making use of the identical job to different NLP fashions, resembling fine-tuned BERT, RoBERTa, or GPT-446,47, to determine configurations best suited for large-scale public worth evaluation.
Finally, the content material structured by way of the CoT prompting proposed right here is as follows: “You are not only a classifier but also an extractor to determine if the input text is related to public values, which include the following (a) industrial advancements, (b) safe society, (c) sustainable environment, (d) job creation, (e) human health, or (f) convenience of life.
The input texts are extracted from a patent describing novel technical ideas. Let’s do it step by step. First, you have to rate 0 to 1 for the suggested six types, marked as (a) to (f) in brief without writing the full name of each type. The output format is ‘a:0,2, b:0.3, c:0.0, d:0.1, e:0.2, f:0.3’. Second, extract relevant phrases from the input text for each type. You have to extract the relevant phrases that make you score high on the first answer for the specific types of public values. With the second answer, if you think there are no related phrases for the specific type, say ‘None.’ The output format that you give is ‘related phrases – (a) extracted phrases related to type a, (b) extracted phrases related to type b, (c) None, (d) …”.
In explicit, the evaluation course of performs iterations for the mannequin to generate outputs for 1000’s of enter texts. That’s why post-processing is important to sum up a bunch of particular person outcomes pushed by the mannequin. To guarantee efficient post-processing of the model-generated textual content, the research consists of particular requests for the output format the mannequin ought to generate. To handle the size of the output textual content effectively, the research suggests symbolizing the public worth varieties as a quantity. This symbolic illustration permits the mannequin to carry out knowledge labeling duties successfully and effectively. By clearly defining the output format and symbolizing the public worth varieties, the research makes an attempt to design prompts that allow the mannequin to label knowledge precisely and in a streamlined method. This method facilitates the environment friendly processing of large-scale textual content knowledge and ensures that the mannequin’s output is well-organized and prepared for subsequent evaluation steps. The particular formatting and symbolization methods assist preserve readability and consistency throughout the outputs, making it simpler to mixture and interpret the outcomes.
Module 3: R&D coverage analysis
In the ultimate module, the research evaluates the outputs of R&D applications funded by the federal government in view of social influence. We analyze qualitative content material from R&D outputs by incorporating R&D initiatives and applications to guage on the R&D coverage degree, as introduced in Fig. 3. The final objective of Module 3 is to comprehensively analyze the outcomes derived in Module 2 and current an analysis of R&D coverage. In the ultimate module, the research assesses the social influence of government-funded R&D applications. By incorporating each R&D initiatives and applications, we consider the outputs on the R&D coverage degree using qualitative content material evaluation. First, we make the most of the public worth evaluation outcomes from Module 2 on the output degree (e.g., patents and publications). These particular person R&D outputs are systematically built-in on the mission and program ranges. This sequential course of elevates the person public worth outcomes to a broader coverage perspective.
The research restructures particular person outputs on the mission and program ranges (Project—Program) to current public worth analysis outcomes on the R&D program degree. The subsequent step entails enhancing the public worth evaluation of the R&D program by incorporating exterior sources. These exterior sources assist overcome the restrictions of relying solely on R&D outputs for public worth evaluation. For occasion, patents and comparable R&D outputs are authored by the builders themselves, and so they could not explicitly handle the know-how’s social impacts or public values. To handle this hole, the research hyperlinks these outputs with exterior sources, resembling evaluate articles or third-party assessments, which supply a broader societal perspective on the novel know-how. Finally, the research comprehensively analyzes the public worth generated by R&D outputs underneath public coverage initiatives. This evaluation informs coverage suggestions for future science and know-how methods, emphasizing public worth strongly. The final objective is to make sure that government-supported R&D efforts obtain technical success and contribute considerably to societal objectives and public welfare.
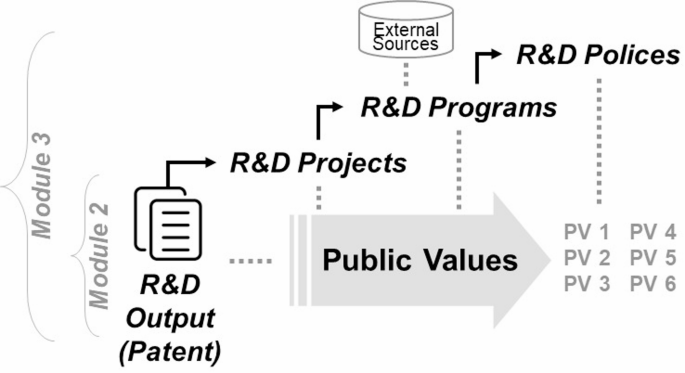
Framework modules linking R&D outputs (patents) to initiatives, applications, and insurance policies, with exterior sources integrated to map and consider public values throughout six classes.
This part incorporates exterior sources to seize “public value” parts that may not be absolutely recognized through R&D outputs alone. These exterior sources can embody reviews from assume tanks, consulting corporations, and opinion items revealed in information media associated to the know-how underneath evaluation. Integrating these exterior sources entails a number of steps: (1) Extracting related paragraphs: In step one, paragraphs associated to the analyzed know-how are extracted from exterior supply paperwork by figuring out key phrases related to the know-how. This course of helps distill related content material from intensive and prolonged paperwork. (2) Analyzing public worth in exterior sources: Next, the extracted paragraphs are analyzed for public values by way of the identical OpenAI-based methodology employed in Module 2. (3) Calculating semantic similarity: The third step entails calculating the semantic similarity between R&D outputs and exterior sources. All textual content knowledge is embedded with a pre-trained language mannequin, and cosine similarity is computed between pairs of embedding vectors. This similarity hyperlinks exterior sources with R&D outputs. (4) Adjusting public worth based mostly on similarity: Finally, the public worth of R&D outputs is adjusted based mostly on exterior sources that exhibit a similarity above a sure threshold. Specifically, scores of the public worth derived from exterior sources are built-in into the public worth kinds of the R&D outputs when a powerful match is recognized.