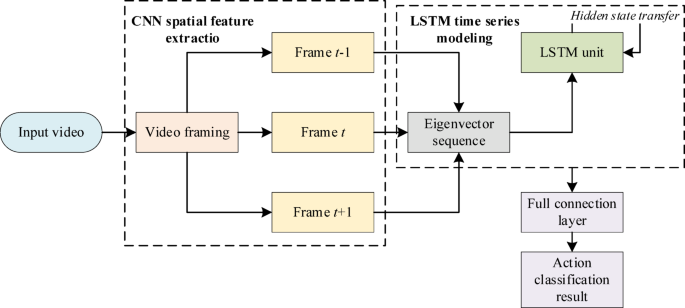
The LSTM-NCS mannequin and human pose estimation
LSTM-NCS is a traditional hybrid DL mannequin, which is broadly used in duties reminiscent of video evaluation and action recognition23,24. This mannequin’s structure is offered in Fig. 1.
Architecture of the LSTM-NCS mannequin.
The mannequin’s workflow in the skiing action recognition job is as follows. First, the NCS extracts the spatial function sequence of every body of the picture. These options are then enter into the LSTM community in chronological order. Based on its inside state, LSTM learns the temporal variation patterns of these spatial options, in the end recognizing full skiing actions reminiscent of “slalom” and “braking”.
In vision-related action recognition duties, uncooked video frames normally include a big quantity of background data irrelevant to the action. Direct processing of such frames will increase the mannequin’s studying problem25. Therefore, to extra successfully signify human motion, the examine first adopts a skeleton key level detection methodology. The core of this methodology is to make use of the human pose estimation mannequin OpenPose to precisely find the pixel coordinates of main human joints in every body of the enter video sequence26,27. These joints type a human skeleton sequence, thereby expressing human pose modifications in the shape of mathematical vectors.
Using the pose estimation mannequin, a human skeleton sequence containing Okay joints may be obtained. For every body, the skeleton knowledge is represented as a set of 2D coordinates of all joints. However, uncooked key level coordinates are vulnerable to the place of the human physique in the picture. Therefore, relative vectors between joints are calculated to extract options from these uncooked coordinates which can be insensitive to place and scale modifications. Assuming there are joints i and j with coordinates ({p}_{i}={(x}_{i},{y}_{i})) and ({p}_{j}={(x}_{j},{y}_{j})) respectively, the vector ({v}_{ij}) from i to j may be described as follows:
$${v}_{ij}={p}_{j}-{p}_{i}=({x}_{j}-{x}_{i},{y}_{j}-{y}_{i})$$
(1)
Equation (1) can successfully describe the spatial path of physique limbs with out being affected by the general translational place of the human physique. In addition, joint angles are additionally calculated as options. This primarily entails setting up vectors utilizing knee joint factors and ankle joint factors, then computing the included angle between them. The included angle θ may be written as:
$$theta = arccosleft( {frac{{u cdot v}}{ v proper}} proper)$$
(2)
(u) and (v) signify two path vectors originating from a typical joint level. The image (cdot) denotes the dot product operation; (left| cdot proper|) denotes the modulus of the vector. The calculated included angle θ can intuitively replicate the bending diploma of the particular joint.
The aforementioned skeleton key level detection and have extraction course of converts high-dimensional video knowledge right into a set of low-dimensional skeleton function sequences. These options function inputs for subsequent fashions to carry out action classification.
The C3D-BiLSTM mannequin based mostly on visible notion
This mannequin optimizes the frequent LSTM-NCS structure. The key enchancment is the introduction of a two-stream mechanism on the enter finish to seize look and movement data individually. In the function fusion stage, a learnable weighting methodology is adopted as a substitute of mounted concatenation; this permits the mannequin to dynamically modify the contribution of every stream based mostly on the enter content material. In the temporal modeling stage, BiLSTM additional integrates bidirectional context to realize an understanding of the entire action cycle. This multi-level structural design permits the mannequin to keep up temporal modeling capabilities. Meanwhile, it enhances the notion and discrimination of transferring targets in snowy eventualities, ensuing in superior efficiency in comparison with frequent LSTM-NCS frameworks.
Model construction
The two-stream enter structure is a typical design in action recognition, the place the RGB stream extracts look options. Moreover, the movement stream is often constructed based mostly on optical circulate fields. Building on this, the movement stream in this mannequin is optimized with a saliency-aware mechanism. This mechanism highlights the movement areas of the skier themselves, thereby weakening the interference from complicated snowy backgrounds. Furthermore, as a substitute of utilizing frequent strategies like concatenation or averaging, the mannequin introduces a learnable weighted fusion module in the function fusion stage. This permits the community to adaptively modify the contribution diploma of the 2 function varieties based mostly on the enter content material.
The total construction of the vision-based C3D-BiLSTM mannequin is a two-stream enter and multi-stage fusion structure. The mannequin absolutely makes use of the looks data and movement data in video knowledge. It then makes use of the optimized LSTM mannequin to extract complicated spatiotemporal dynamic options of skiing actions. The mannequin’s construction is revealed in Fig. 2.

Structure of the visible perception-based C3D-BiLSTM mannequin.
In Fig. 2, the mannequin’s enter consists of two knowledge streams. The first stream is the unique RGB video body sequence, which accommodates ample look visible data. The second stream is the saliency notion stream. This knowledge stream is applied by calculating the optical circulate subject between consecutive frames. Its goal is to extra successfully specific the movement patterns and a spotlight areas of skiing actions, highlighting the dynamic modifications brought on by the skier’s actions. Both knowledge streams are processed in completely different branches of the C3D mannequin.
After fusing the spatiotemporal function sequences output by the 2 C3D branches, the fused function sequence is enter into the BiLSTM mannequin to finish temporal modeling. The BiLSTM makes use of a totally linked layer and a Softmax classifier to output the ultimate action classification outcomes.
The introduction of the saliency notion stream
In skiing action recognition duties, background interference and look modifications can distract the mannequin. Thus, relying solely on uncooked RGB body sequences might fail to extract movement dynamics28,29. In gentle of this, the proposed methodology introduces a saliency notion stream, and its calculation is predicated on the optical circulate subject. Optical circulate fields can specific the movement state of pixels between consecutive frames. They emphasize native movement patterns brought on by the skier’s actions and lowering interference from static backgrounds30. Optical circulate calculation is a regular methodology in dynamic video evaluation used to explain pixel movement between consecutive frames. Based on this, the examine additional makes use of the magnitude of optical circulate vectors to generate a saliency weight map. This weight map is then used to boost the illustration of movement areas.
Specifically, a dense optical circulate algorithm generates the saliency notion stream. This algorithm emphasizes that the brightness worth of a pixel stays unchanged between adjoining frames. Assuming the brightness worth of pixel p in the body at time t is (F(p,t)). At time (t+{Delta}t), the pixel strikes to a brand new place (p+delta p) whereas sustaining its brightness worth, resulting in the next equation:
$$F(x,y,t)=F(x+{delta}_{x},y+{delta}_{y},t+{Delta}t)$$
(3)
(F(x,y,t)) represents the picture brightness worth at place ((x,y)) and time (t). ({delta}_{x}) and ({delta}_{y}) denote the displacement elements of the pixel in the (x) and (y) instructions, respectively. By increasing Eq. (3) utilizing first-order Taylor collection and ignoring higher-order phrases, the fundamental constraint equation of optical circulate is derived:
$${F}_{x}cdot{delta}_{x}+{F}_{y}cdot{delta}_{y}+{F}_{t}=0$$
(4)
({F}_{x}) and ({F}_{y}) denote the spatial gradients of the picture in the (x) and (y) instructions, respectively, and ({F}_{t}) is the temporal gradient. Here, ({delta}_{x}) and ({delta}_{y}) not solely signify the displacement elements of the pixel but in addition type the optical circulate vector collectively, which signifies the pixel’s movement velocity.
Subsequently, a worldwide optimization methodology is used to resolve the optical circulate vector. This primarily entails minimizing an power operate to acquire a easy optical circulate subject. The type of the power operate (E) is as follows:
$$E = iint {left[ {(F_{x} delta _{x} + F_{y} delta _{y} + F_{t} )^{2} + gamma left( {left| {nabla delta _{x} } right|^{2} + left| {nabla delta _{y} } right|^{2} } right)} right]dxdy}$$
(5)
The first time period is the information time period, which ensures the optical circulate satisfies the brightness fidelity assumption. The second time period is the smoothness time period, which enforces spatially easy modifications in the optical circulate subject. (gamma) is a regularization parameter that balances the significance of the information time period and the smoothness time period. (nabla{delta}_{x}) and (nabla{delta}_{y}) signify the gradients of ({delta}_{x}) and ({delta}_{y}), respectively.
In addition, a saliency weight map is generated based mostly on the optical circulate vector’s modulus to spotlight areas with intense movement. The calculation methodology of the saliency weight map (W(x,y)) is:
$$W(x,y)=textual content{e}textual content{x}textual content{p}left(alphacdotsqrt{{delta}_{x}(x,y{)}^{2}+{delta}_{y}(x,y{)}^{2}}proper)$$
(6)
(W(x,y)) denotes the saliency weight at place ((x,y)). (alpha) is a scaling issue that adjusts the load distribution’s sensitivity. ({delta}_{x}(x,y)) and ({delta}_{y}(x,y)) are the optical circulate vector elements at this place. The saliency weight map calculated by way of Eq. (6) is actually a matrix of the identical dimension because the optical circulate subject. The weight worth at every place displays the depth of movement in that area between consecutive frames. Regions with bigger weights point out extra apparent pixel movement, possible equivalent to the skier’s limbs or skis. Regions with small weights possible signify static snow, timber, or distant backgrounds. In subsequent function extraction, these weights are multiplied by the corresponding optical circulate options. This forces the mannequin to pay larger consideration to the transferring topic and suppress interference from irrelevant backgrounds. This differs from conventional two-stream networks that instantly use uncooked optical circulate photographs, treating your entire picture equally. In distinction, this examine focuses particularly on movement data by way of saliency weights.
The introduction of the above saliency notion stream gives the mannequin with direct movement data. Thus, it may possibly higher assist the mannequin distinguish skiing actions with comparable appearances however completely different movement patterns.
Dual-stream C3D fusion of spatial semantic options
Feature fusion is a crucial step in multi-stream networks. Common approaches embrace direct concatenation or weighted averaging. In skiing action recognition, completely different technical actions depend on look and movement options to various levels. For instance, the distinctive posture of the skis throughout a plough brake is primarily mirrored in look modifications, whereas a parallel flip depends extra on steady physique movement patterns. Simple function concatenation or common fusion struggles to adapt to those dynamic modifications and might simply lead the mannequin to over-reliance on one kind of data for sure actions. Therefore, this examine adopts a learnable weighted fusion methodology. This permits the mannequin to mechanically modify the weights of the RGB stream and the saliency stream based mostly on the content material of the enter video. It combines look and movement data extra flexibly, thereby bettering the discrimination means for various skiing actions.
In the two-stream C3D mannequin construction, the RGB stream and saliency notion stream extract appearance-spatial options and motion-semantic options from video sequences, respectively. To absolutely make the most of these two varieties of data, efficient integration is required. In conventional two-stream architectures, the movement stream usually makes use of optical circulate maps instantly as enter. The options extracted replicate the general movement distribution of pixels. The proposed saliency-aware stream additional introduces a spatial weighting mechanism based mostly on optical circulate. This permits the community to deal with movement data from completely different areas in a extra differentiated method. Therefore, in the fusion stage, the mannequin combines not simply look and movement options. It is much more of a movement illustration that’s adjusted through saliency weights to be nearer to the essence of the skier’s actions.
The fusion course of begins with processing the output options of the 2 C3D branches. It may be assumed that the function extracted by the RGB-stream and saliency-perception-stream C3D is denoted as ({F}_{r}) and ({F}_{s}). They are each 3D tensors. However, ({F}_{r}) accommodates spatial and look data in the video body sequence, ({F}_{s}) emphasizes the movement patterns of skiing actions. Before fusion, the L2 normalization methodology scales each tensors to a fusion-compatible vary. The calculation of normalized options (stackrel{sim}{{stackrel{sim}{F}}_{r}}) and ({stackrel{sim}{F}}_{s}) are:
$$left{start{array}{c}{stackrel{sim}{F}}_{r}=frac{{F}_{r}}{parallel{F}_{r}{parallel}_{2}}{stackrel{sim}{F}}_{s}=frac{{F}_{s}}{parallel{F}_{s}{parallel}_{2}}finish{array}proper.$$
(7)
∥⋅∥2 denotes the L2 norm, derived from the sq. root of the sum of the squares of all tensor components. Normalization avoids extreme variations in function vector magnitudes that would have an effect on fusion efficiency.
Subsequently, weighted summation is adopted for function fusion. The fused function ({F}_{fusion}) is obtained by way of a linear mixture of the 2 normalized options, with the calculation components:
$${F}_{fusion}={lambda}_{r}cdot{stackrel{sim}{F}}_{r}+{lambda}_{s}cdot{stackrel{sim}{F}}_{s}$$
(8)
({lambda}_{r}) and ({lambda}_{s}) are the fusion weight coefficients of the RGB stream and saliency notion stream, respectively. These weight coefficients function learnable parameters of the mannequin and may be mechanically adjusted by way of backpropagation throughout coaching.
To additional improve the soundness of fusion weights, the Softmax constraint is utilized to the weights throughout coaching. The last values of ({lambda}_{r}) and ({lambda}_{s}) are decided by:
$$left{ {start{array}{*{20}l} {lambda _{r} = frac{{exp left( {z_{r} } proper)}}{{exp left( {z_{r} } proper) + exp left( {z_{s} } proper)}}} hfill {lambda _{s} = frac{{{textual content{exp}}left( {z_{s} } proper)}}{{{textual content{exp}}left( {z_{r} } proper) + {textual content{exp}}left( {z_{s} } proper)}}} hfill finish{array} } proper.$$
(9)
({z}_{r}) and ({z}_{s}) are the unique learnable scalar parameters of the fusion weights. Through the Softmax operate, the load coefficients are normalized to the interval [0,1], stopping extreme suppression of options from both stream throughout fusion.
Dynamics evaluation based mostly on BiLSTM
In skiing, actions usually exhibit distinct continuity and periodicity. A whole flip, for instance, consists of a number of phases reminiscent of preparation, entry, and exit. A unidirectional LSTM can solely infer based mostly on previous data. It struggles to seize predictive options of future actions current in the ending section. In distinction, BiLSTM analyzes sequential data from each instructions. It achieves a extra complete understanding of the beginning, transition, and finish of actions. This permits for extra correct differentiation between actions that look comparable however have completely different temporal buildings. This modeling functionality for full action cycles permits the mannequin to show larger stability in complicated and dynamic skiing eventualities.
After fusing spatial-semantic options, the BiLSTM mannequin is used to investigate and perceive the temporal variation patterns of actions.
The BiLSTM mannequin consists of two separate LSTM layers: ahead and backward. For every time step t, the ahead LSTM layer processes the sequence from left to proper, extracting historic data as much as the present second. The backward LSTM layer processes the sequence from proper to left, capturing contextual data from the long run to the present second. Each LSTM unit controls data transmission by way of a gating mechanism, together with enter, overlook, and output gates31. The enter gate regulates how a lot present enter data is up to date to the cell state, expressed as:
$${m}_{t}=sigma({W}_{lm}{l}_{t}+{W}_{gm}{g}_{t-1}+{omega}_{m})$$
(10)
({m}_{t}) is the enter gate activation vector at time step t; σ represents the sigmoid activation operate; ({l}_{t}) stands for the enter function on the present time step; ({g}_{t-1}) refers back to the hidden state from the earlier second; ({W}_{lm}) and ({W}_{gm}) are the load matrices equivalent to the enter and hidden state, respectively; ({omega}_{m}) denotes the bias time period.
The overlook gate is calculated as:
$${f}_{t}=sigma({W}_{lf}{l}_{t}+{W}_{gf}{g}_{t-1}+{omega}_{f})$$
(11)
({f}_{t}) refers back to the overlook gate activation vector at time step t; ({W}_{lf}) and ({W}_{gf}) are the corresponding weight matrices; ({omega}_{f}) is the bias time period. Through the adjustment of the overlook gate, the mannequin can autonomously choose to retain or discard historic data related to present action recognition.
Based on the outputs of the enter and overlook gates, the cell state is up to date by Eq. (12):
$${c}_{t}={f}_{t}odot{c}_{t-1}+{i}_{t}odottext{t}textual content{a}textual content{n}textual content{h}({W}_{lc}{l}_{t}+{W}_{gc}{g}_{t-1}+{omega}_{c})$$
(12)
({c}_{t}) and ({c}_{t-1}) are the present and former cell states, respectively; ⊙ is element-wise multiplication; (textual content{t}textual content{a}textual content{n}textual content{h}) is the hyperbolic tangent activation operate; ({W}_{lc}) and ({W}_{gc}) denote the corresponding weight matrices; ({omega}_{c}) refers back to the bias time period. Finally, the output gate controls how a lot of the up to date cell state is transmitted to the hidden state.
With the BiLSTM, the mannequin can concurrently make the most of each historic and future contextual data of skiing actions.